Introduction
Humans have been interested in cryptography, or the science of encoding/decoding secret messages to one another, for at least as long as recorded history.¹ Yet this field has become increasingly important and relevant to everyone in the digital age. Modern cryptography lets us access web services securely without revealing sensitive personal information. It secures billions of dollars in e-commerce transactions as well as SWIFT interbank transfers. Most recently, cryptography forms the basis for an entirely new financial paradigm based on cryptocurrencies such as Bitcoin.
Although Internet users rely on it every day, cryptography still seems mysterious and arcane. Fortunately, we don’t have to know how it works to appreciate its benefits. But a little understanding can help all of us be more informed users. And if you’re curious (like me), knowing how something works under the hood can also bring about a sense of fulfillment or even joy.
This post is the first in a series about the cryptography used in blockchains and digital currencies. The first primitive that we’ll examine are cryptographic hash functions. Cryptographic hash functions are so important that they are often referred to as the “workhorses” of modern cryptography. For cryptocurrencies, these functions form the basis for consensus algorithms such as proof-of-work.
A quick disclaimer: this post (and series) is written for the interested, educated layperson rather than the academic researcher. So I may be a little “looser” with the formal definitions to get the point across. But for those that are interested in a more formal treatment of the topic, I’ll link to some resources at the bottom of the article.²
What is a hash function?
A hash function is a deterministic mathematical function that maps some input of arbitrary size to a fixed-length output. A simple example is a function that returns a number based on the first (English) letter of your last name. No matter how long your last name is, the output of that function will be some (at most 2-digit) number between 1 and 26. And because the function is deterministic, the same input will result in the same output every time.
Although the input length of a hash function doesn’t have to be longer than the output, we usually want hash functions that compress. For our example above, we took every possible combination of English letters that could constitute a last name and mapped them to 26 possible options. This data is much easier to search and store than the full-length inputs.
Of course, the astute reader has realized an obvious problem with my example hash function above. If two last names start with the same letter, the hash value will be the same. This is called a collision, and in this case, we cannot tell two people apart based on the hash values of their names alone. So even though our hash function has helped us preserve storage space, it compresses too much information to be useful.
Cryptographic Hash Functions
Cryptographic hash functions were formalized in the 1970s and since then have been integrated into nearly everything from symmetric key derivation to zero-knowledge proofs. They are a subclass of the broader family of hash functions which are designed to help in cryptographic schemes. In particular, collisions should be hard³ to find under a variety of circumstances. The different flavors of collision resistance are defined below.
Collision Resistance — For the hash function H(x), it should be hard to find any collisions at all. That is, it should be hard to find two inputs x_1 and x_2, where the outputs are the same (H(x_1) = H(x_2)). Because the possible inputs of this function outnumber possible outputs, there must be collisions. But with a large enough output space, the probability of a collision should be negligible.
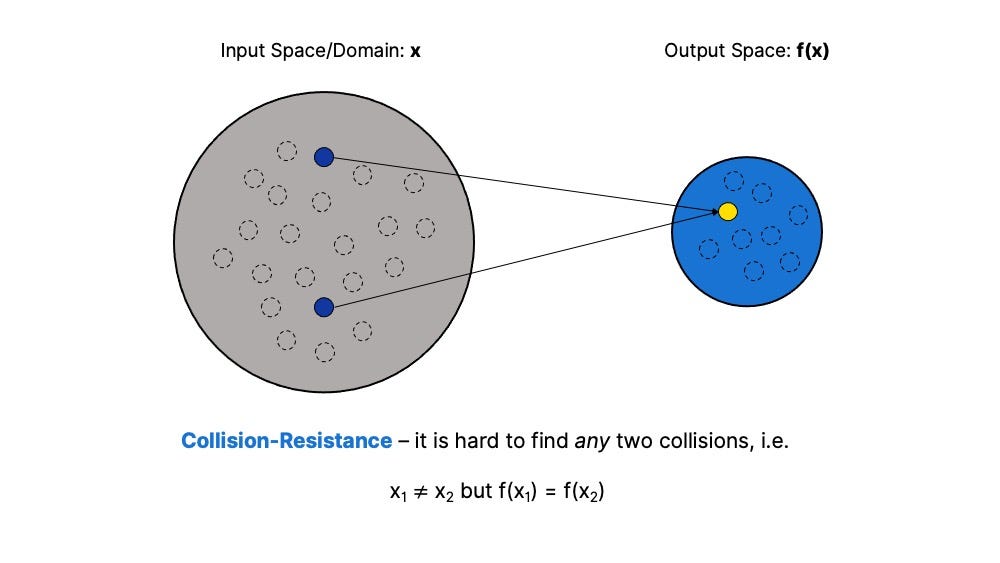
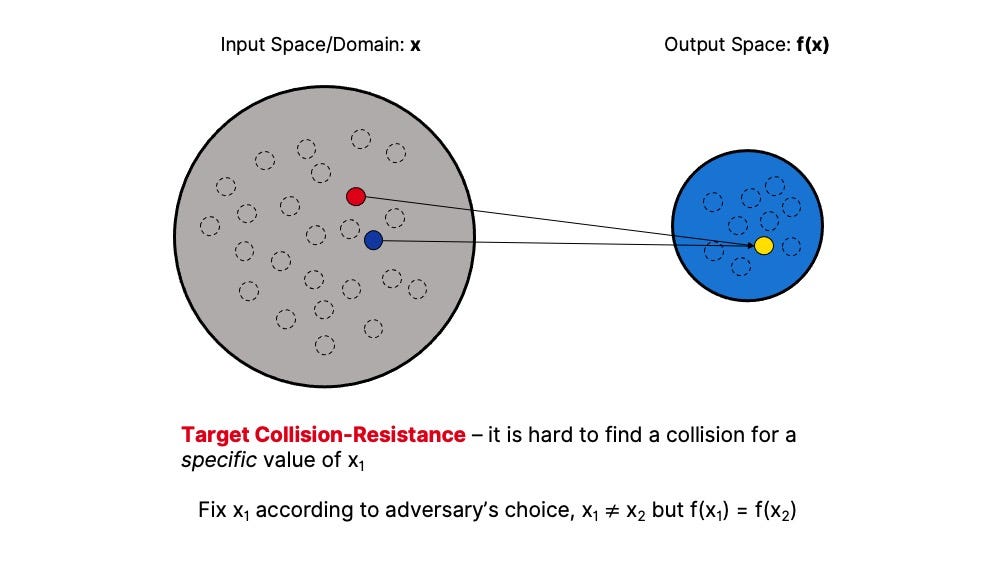
Target Collision Resistance — The hash function H(x) is target-collision resistant if it is difficult to find a collision for an adversary’s choice of the input value.
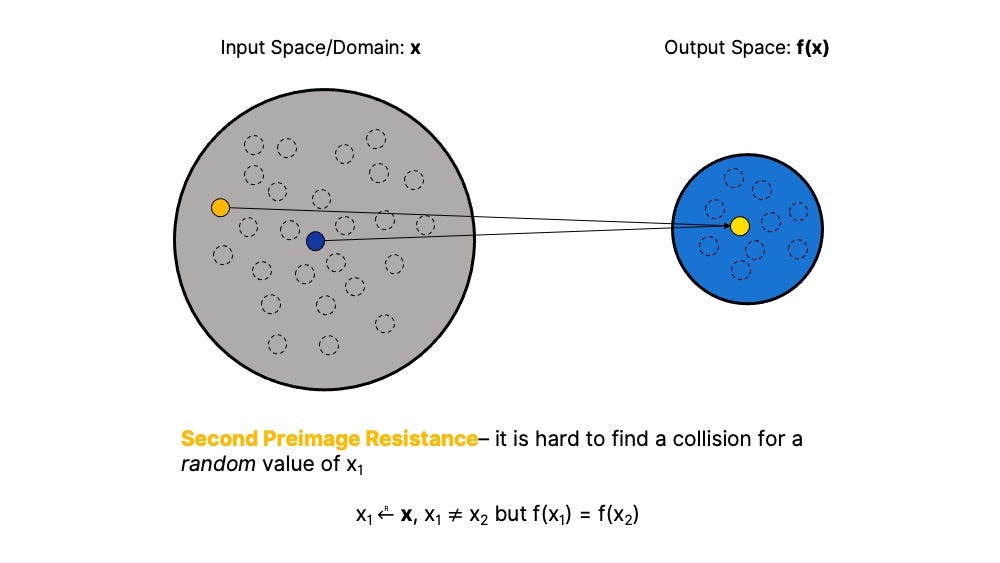
Second Preimage Resistance — The hash function H(x) is second-preimage resistant if it is difficult to find a collision for a randomly selected input value. In other words, second preimage resistance describes the extent to which each output is effectively unique.
Preimage Resistant — it’s hard to find x if all you know is the output of a hash function H(x). In other words, preimage resistance means that it is difficult to “reverse engineer” the output of a CRHF to find its input. Functions that are preimage resistant are also sometimes called one-way functions⁴, which means they are effectively irreversible if you only see the output.
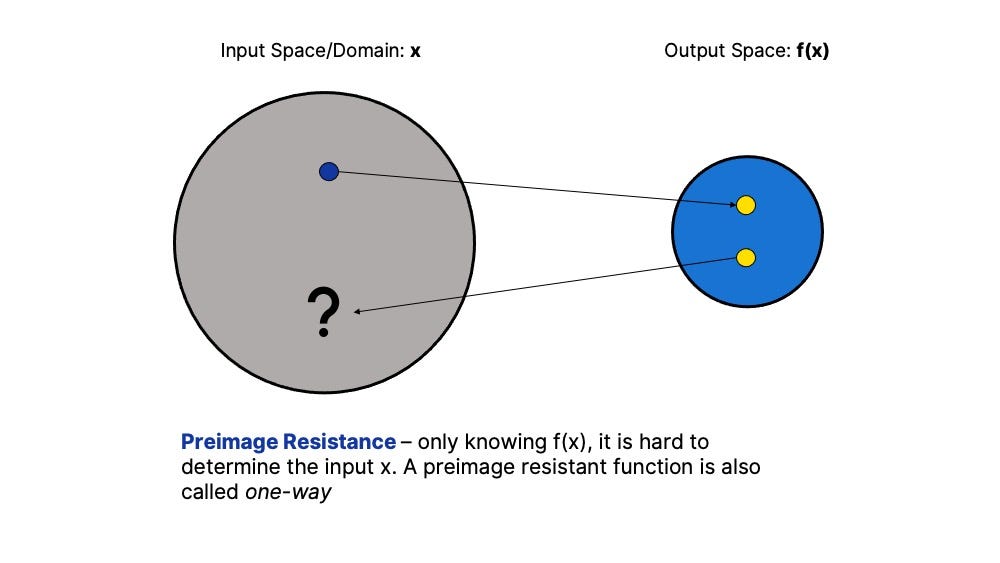
I ordered the list this way because these properties are hierarchical. So collision-resistance implies target collision-resistance, which implies second preimage resistance, etc. But the reverse is not true. Just because a function is target collision resistant does not mean that it is necessarily collision-resistant.
Not every cryptographic hash function/scheme has these properties. There are a few other informal properties of a good practical cryptographic hash function implied by the list above. For example, even a small change to the input should produce a large, unpredictable change in the output. This “avalanche effect” is a consequence of preimage resistance that makes proof-of-work consensus schemes (described next) secure.
Hash Functions and Proof-of-Work
For cryptocurrencies that use Proof-of-Work mining for consensus (like Bitcoin), the properties we care most about are preimage resistance and second-preimage resistance. Before we can understand why we need to go into slightly more detail about how a proof-of-work consensus algorithm works using Bitcoin as an example.⁵
In the Bitcoin network, nodes maintain a global ledger of balances corresponding to different public keys.⁶ They also keep a history of all historic transactions organized into blocks. Each block contains a list of transactions that occurred within a given period, as well as a reference to the previous block. The previous block header is just the output of a hash function where the inputs were the contents of that block.
Nodes on the Bitcoin network can produce blocks of new transactions to add to the blockchain in exchange for a reward (denominated in BTC). So they have to create a new block containing transactions and a new block header. But other nodes on the network won’t accept just any block header. They will only accept a block with a header (the output of a hash function) contains some large number of leading 0’s (like 0000000000000000000bffeea5b705bbba0902579ab91da102e348be59d46310). This is unlikely to happen for any given set of inputs. But if a hash function is deterministic, how can a Bitcoin miner create a hash function output with the correct structure?
This is where the proof of work puzzle comes in. Besides the transactions and previous header, Bitcoin miners add a single extra value called a nonce.⁶ If the resulting output does not meet the “target” criteria, then the miner increments the nonce and runs the function again. This process is repeated over and over until the hash function produces a value that does.
The above process is what we call “mining” in proof-of-work blockchains like Bitcoin. Nodes run the hash function over and over, with the same inputs except for the nonce. Once they find a nonce that, combined with individual transactions and previous block header, results in a correct number of leading zeroes⁷, they can submit it to the network and claim their block reward.
Cryptographic hash functions are the magic ingredient to this process. Recall that the property of preimage resistance means that the output of the hash function should be unpredictable. In other words, it should “seem” random. So miners can’t just start with the target hash value and work backward to compute what the value of the nonce input should be. And the problem of finding a target output for the hash function is just as hard no matter how many prior iterations have been performed.
Meanwhile, second-preimage resistance means that it is hard to find collisions for a randomly chosen input (e.g. previous block header and transactions). In practical terms, that means each output of the hash function is reliably unique. Finally, target collision resistance guarantees that it’s hard for an adversary to find any specific message that results in a specific hash value. This ensures that no one can arbitrarily swap out a part of the blockchain for another part later. And because each new block header references the previous block, which references the previous block, so on and so forth, the integrity of the entire ledger history is maintained.
Conclusion
Although this post has focused only on cryptographic applications, hash functions are used for a wide variety of purposes. For example, they are used to detect changes in large files. Given a large input (like an entire database), preimage resistance (and the associated “avalanche effect”) means that even changing a single character in the entire file results in a different hash output. So it’s possible to store and compare hash outputs much more efficiently than checking the file itself.
In terms of other cryptographic applications, a major advantage of hash functions is that they are quantum resistant. The reason for this is that reverse-engineering the output of the hash function is as hard for a quantum computer as it is for a non-quantum computer.⁸ Other cryptographic primitives (like digital signature schemes used in Bitcoin and other cryptocurrencies) are based on problems that are easy for quantum computers to solve, but hard for normal computers. So while quantum computers are a threat to other aspects of many existing cryptosystems, the cryptographic hash functions we use today should remain secure. Also, many existing cryptography schemes can be altered to use hash functions, providing a foundation for secure cryptography going into the future.
As we’ve seen, cryptographic hash functions are the cornerstone of proof-of-work mining in Bitcoin and other cryptocurrencies. The properties of target collision resistance, second preimage resistance, and preimage resistance of cryptographic hash functions ensure the security, decentralization, and “fairness” of proof-of-work consensus. Some consider cryptocurrency mining as a “waste” of energy, claiming that the brute-force nature of proof-of-work Bitcoin-like systems is inefficient. They have suggested alternatives based on “useful” work, like protein-folding or searching for large prime numbers. But none of the proposed problems have the properties enumerated above. So they cannot ensure security and decentralization to the same degree.
As mentioned in the introduction, this is the first piece in a series of demystifying cryptographic primitives. I chose hash functions since they are essential to proof-of-work mining in Bitcoin, Ethereum, and many other cryptocurrencies. Beyond blockchains, they are also because they are so ubiquitous in cryptography more broadly. But despite their importance, they are not magical. Just a little bit mathematical 🙂 So hopefully, this essay helped clarify what these functions are and why they are important. I hope it also inspired you to learn more about the increasingly important field of cryptography. If there are any suggestions for what I should cover next, or if you have feedback on this piece, please comment below!
Endnotes:
[1] For a great history of cryptography, I highly recommend David Kahn’s book The Codebreakers: The Comprehensive History of Secret Communication from Ancient Times to the Internet
[2] For a more in-depth treatment of this topic, I highly recommend Stanford professor Dan Boneh’s introductory cryptography course on Coursera. For an even deeper look, I recommend the text The Theory of Hash Functions And Random Oracles by Arno Mittelbach and Marc Fischlin
[3] This term refers to the difficulty of finding collisions for an “efficient” adversary, which means an adversary bounded by a polynomial runtime. If this is unfamiliar terminology, don’t worry about it since it doesn’t matter that much for the purpose of this article. But if you want to go down the rabbit hole, check out this Wikipedia entry about computational complexity
[4] One-way functions are one of the most fundamental cryptographic primitives. Nearly every cryptographic scheme relies on one-way functions in some way.
[5] Bitcoin uses a hash function called SHA-256, which is time-tested, NIST-certified cryptographic hash function that has all of the properties described above. Other blockchains sometimes use different functions for proof-of-work (for example, Ethereum uses Keccak-256). But even though the implementation details are different, the overall scheme looks roughly the same for any proof-of-work network as long as the hash function used is a cryptographic hash function with the properties listed above
[6] “Nonce” is short-hand for a value that is used “not more than once”
[7] In order to keep block production times relatively constant, Bitcoin and most other proof-of-work blockchains have a dynamic “difficulty” parameter. This difficulty defines how hard it is to find a target hash output, i.e. a higher difficulty requires a larger number of leading zeroes
[8] Again, hardness here refers to efficient adversaries. But certain algorithms that are inefficient on traditional computers are actually quite efficient with quantum computers (see Shor’s Algorithm)